
유명 코미디언 사라 실버맨(Sarah Silverman)을 포함한 작가들이 오픈AI와 메타 두 회사를 상대로 집단 소송을 제기하며 인공지능 산업이 곤경에 처하게 되었다.
고소인들은 오픈AI와 메타가 ”수천 명의 작가와 다른 이들의 저작권 보호받는 글을 어떠한 동의나 보상, 인정 없이” 재조합했다고 주장한다.

오픈AI의 DALLE 예술 생성 모델 출시 이후 일반 대중에게 인공지능 도구의 인기가 폭발적으로 증가한 후 AI 기술은 소유자의 허락 없이 지적재산권인 저작물을 도용한다고 비판받았다.
오픈AI와 메타 상대로 한 고소장 내용은?
원고는 챗GPT의 프롬프트와 답변을 저작권 침해 증거물로 제출했다. 예를 들어, 폴 트렘블래이(Paul Tremblay)의 소설 “세상 끝 오두막(The Cabin at the End of the World)”의 줄거리를 묻자 소설 초반 줄거리를 설명하는 420단어짜리 답변이 돌아왔다. 이후 추가 줄거리를 묻는 프롬프트를 입력하자 마지막 결말을 포함해 소설의 주요 내용을 모두 추출할 수 있었다.
여러 작가로 이루어진 대규모 집단이 초기 소송을 제기한 지 2주 뒤에 사라 실버맨 역시 고소장을 제출하며 작가들의 싸움에 동참했다. 그녀는 그녀의 책 “더 베드웨터(The Bedwetter)“를 비롯해 여러 작가의 저작물이 일명 ‘그림자 도서관(‘shadow library)‘으로 불리는 저작권 보호 서적과 기사 등으로 가득찬 대형 불법 데이터베이스에서 수집되었다고 주장했다.
작가들의 주장은 사실일까?
오픈AI가 모델을 훈련하는 데 사용하는 모든 자료의 출처를 직접적으로 알지 못하는 상황에서 해당 서적들이 사용되었다고 확언하기는 힘들다. 하지만 작가들이 그랬던 것처럼 챗GPT에 질문하여 정보를 얻을 수는 있다.
물론 실버맨의 책 1장 내용을 달라는 요청을받았을 때 챗GPT는 저작권 보호되는 서적이나 콘텐츠에 접근할 수 있는 능력이 없다고 주장한다.

질문을 조금 다르게 하려면 살짝 다른 답변을 제안하며 해당 부분이 훈련된 데이터셋에 기록되지 않았다고 답변한다. 실버맨의 베드웨터 문단을 입력해 어느 책에서 나온 내용인지 물었을 때조차 원하는 답변을 얻을 수 없었다.
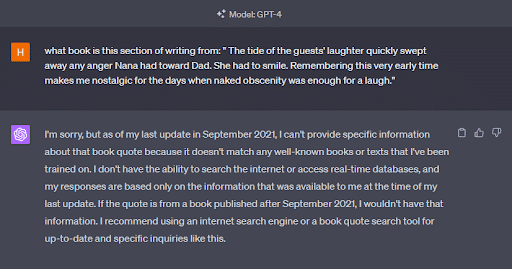
그렇다면 챗GPT가 이 책들로 실제로 훈련되지 않았다는 뜻일까? 꼭 그렇지만은 않다. 오픈AI를 고소하지 않는 작가들의 책은 쉽게 인식하는 것으로 드러났기 때문이다. 챗봇은 지적재산권으로 보호받는 브랜던 샌더스(Brandon Sanderson)의 책 “미스트본: 최후의 제국(Mistborn: The Final Empire)”의 특정 문단으로부터 책 제목을 인식할 수 있었다.
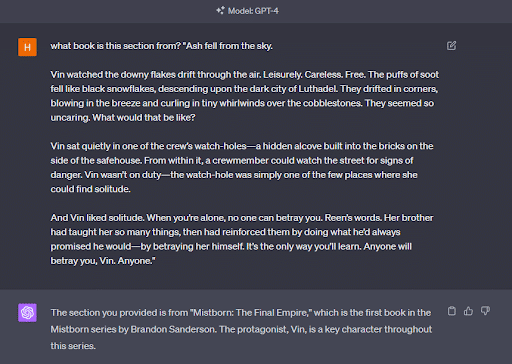
하지만 이러한 답변으로부터 반드시 GPT-4가 책 내용으로 훈련되었다고 유추할 수는 없다. 프롬프트에 입력된 문단의 경우 다소 길었으며 독특한 캐릭터 이름이 포함되어 후기 사이트 등 인터넷에 존재하는 다른 콘텐츠로 책 제목을 찾는 것이 가능할 수 있기 때문이다.
하지만 GPT-4는 펭귄 북스에서 출판한 ‘마스터와 마가리타(The Master and the Margarita)’의 문단을 식별하는 데에도 성공했다. 이 경우 등장인물의 이름도 포함되지 않은 매우 짧은 문단이었는데도 불구하고 인식했다.

챗GPT의 저작권법 위반을 판별하기 위해 해당 접근 방식을 적용하는 데 있어서의 어려움은 정보가 정확히 어디서 유래되었는지 알 수 없다는 데 있다. 그래도 챗 GPT가 일부 저작물의 글 일부분 이상은 접근할 수 있었던 것으로 추측된다.
공정 사용 원칙이 적용될까?
오픈AI와 메타가 모델 개발에 지적재산권을 남용했는지 결정하는 사안도 중요하지만, 법적으로는 문제가 되지 않을 가능성이 있다. 인공지능 모델 개발 회사들은 비록 저작권 저작물이 모델 개발에 사용되었다 하더라도 미국 저작권법 아래 ‘공정 사용’ 사례에 해당한다고 주장한다.
공정 사용 원칙에 따르면 생성물이 변형되었으며, 저작권자에게 피해가 발생하지 않으며, 상업적 목적으로 사용되지 않는 경우 허락 없이 저작권 저작물을 사용할 것을 일반적으로 허용한다. 하지만 오픈AI를 비롯한 대부분의 AI 모델 개발사는 상업적 이익을 위해서 모델을 판매하고 있기 때문에 마지막 요건을 충족하지 못한다.
미국 대법원 역시 최근 앤디워홀 재단과 골드스미스의 소송(Andy Warhol Foundation for the Visual Arts v. Goldsmith)에서 해당 조항을 판시한 바 있다.

법원은 워홀의 오렌지 프린스 작품이 사진작가 린 골드스미스의 원작을 변형하긴 했지만, 상업적 이용을 의도하였기 때문에 공정 사용 원칙에 따라 보호되지 않는다고 판결했다.
하지만 아직 공정 사용을 판별하는 구체적 요인에 대한 명확한 합의가 없으며 일부 여론은 상업적 이익 목적에도 불구하고 인공지능 모델이 공정 사용 사례에 해당한다고 주장한다.
소송의 결말은 어떻게 될까?
아직 원고의 정확한 근거가 불명확하지만, 오픈AI가 저작권 저작물을 상업적 용도로 사용했다는 증거는 일부 확보한 것으로 보인다. 하지만 사건은 전통 저작권법의 틀에 맞지 않는 최첨단 기술을 다루는 만큼 단순한 소송이 아닐 것으로 전망한다. 메타와 오픈AI가 승소한다고 하더라도, 이번 소송을 통해 드디어 인공지능 모델이 어떻게 훈련되는지 공개될 것으로 기대된다.
관련기사:
- AI 도입이 어려운 사업체들을 위한 AI 쉽게 적용하는 방법
- 강력한 개미 투자자 커뮤니티, 월 스트리트 밈즈 – 사전 판매 1,400만 달러 돌파
- 챗GPT가 예측한 도지코인 강세 전망, 이 두 밈코인도 상승 예측
월 스트리트 밈즈 (WSM) - 최신 밈 코인

- 팔로워가 백만 명이 넘는 커뮤니티 보유
- NFT 프로젝트 숙련자들이 창립한 프로젝트
- 사전판매 현재 절찬리 진행 중 - wallstmemes.com
- 사전판매 런칭 당일에만 30만 달러 이상 모금한 인기 프로젝트
